Les inventaires de fonds d’archives : une ressource à valoriser et à connecter
Les inventaires sont des ressources précieuses, pour les archives et les chercheurs, en tant que représentation synthétique du matériau de recherche. Si la production de ces inventaires se fait aujourd’hui avec les outils informatiques, beaucoup d’entre eux ont été réalisés dans le passé à la machine à écrire.
De nombreux inventaires, en format papier, sont d’ores et déjà numérisés, parfois océrisés, et permettent de recenser et d’exploiter ces ressources via des inventaires en ligne. Le passage d’une image numérisée en données, traitable informatiquement, est un autre enjeu important de cette exploitation des inventaires de fonds d’archives. Cette étape nécessite la structuration des données afin d’obtenir un objet informatique, facilement sérialisable au format TEI, et intégrable à une base de données. Il devient alors possible, d’exploiter cette ressource en la triant, la filtrant, de l’enrichir en la liant à d’autres données.
Un exemple d’inventaire à valoriser
Nous avons récemment eu l’opportunité de traiter un inventaire d’un fonds d’archive numérisé (un format image) pour Archival City, dans le but de le rendre exploitable et manipulable par des chercheurs, à l’aide d’un simple tableur et intégrable à leur plateforme AtoM.
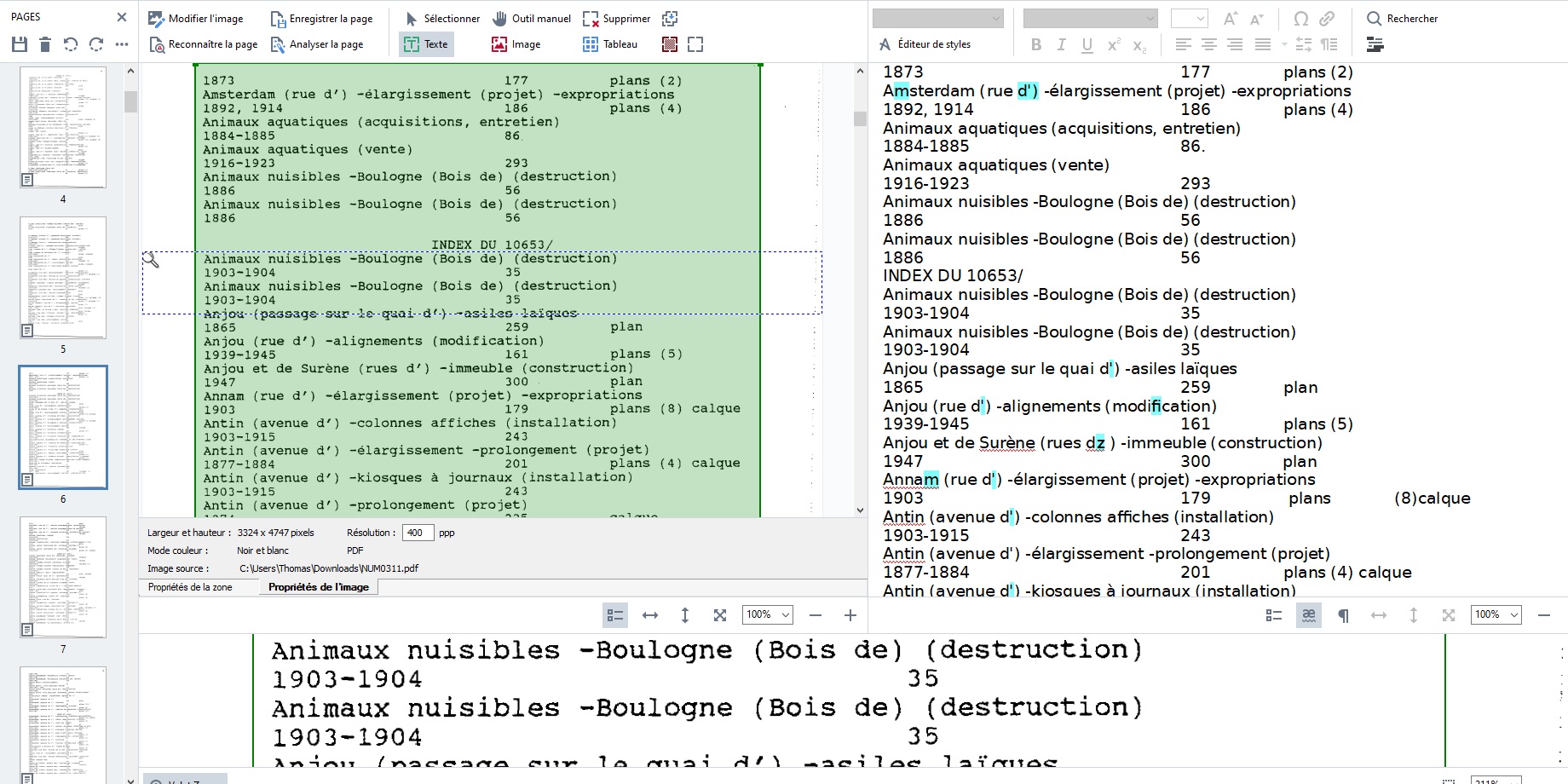
L’inventaire contenait 4 500 entrées répertoriant les travaux d’aménagement entre 1860 et 1930, issus du fonds PEROTIN/10653 des Archives de Paris. Le document que vous pouvez voir ci-dessous est structuré autour d’une paire de lignes. La première décrit l’intitulé et une partie du contenu du document. La seconde contient des informations rattachées à la première : dates, carton d’archives, type de documents présent, nombre de pages.

L’enjeu consiste à rendre exploitable la seconde ligne, dite d’information, pour pouvoir les manipuler comme un ensemble cohérent, et non plus comme un simple fichier texte où chaque chaîne de caractère est isolée.

Océrisation du document
Le document numérique a quelques défauts qui impactent son océrisation. Par exemple, son mauvais cadrage et son axe en diagonale font sauter plusieurs lettres et posent problème pour reconnaître les inter-lignes, occasionnant des fusions de lignes inopportunes. Nous avons corrigé cela de manière semi-automatisée à l’aide de Python, un langage de programmation.
Les langages de programmations nous permettent d’effectuer des vérifications et certaines corrections de façon plus rapide pour aider ce travail. Dans le cas de plus nombreuses données, la perte de temps que peut entraîner l’écriture de lignes de code, est compensée par le volume de données auxquelles s’appliquent les programmes.
Traitement et structuration des données
La structuration doit permettre de transformer l’inventaire océrisé, sous forme de document texte, en données respectant le modèle voulu par le chercheur. Pour ce faire, une entrée dans la base de données doit correspondre à deux lignes et disposer des variables suivantes : description (première ligne), dates, carton, type de document, nombre de pages.
La première étape de la structuration consiste à identifier chaque couple de lignes représentant une entrée, pour grouper chaque paire en une seule entité, et non plus des suites de lignes.
La seconde étape est une suite de traitements sur la partie « informations » de chaque entité. Nous cherchons simplement à diviser les informations en quatre groupes : les dates, les emplacements des documents, les types de documents, le nombre de pages. Chaque mot de la chaîne de caractères est traité individuellement et catégorisé.
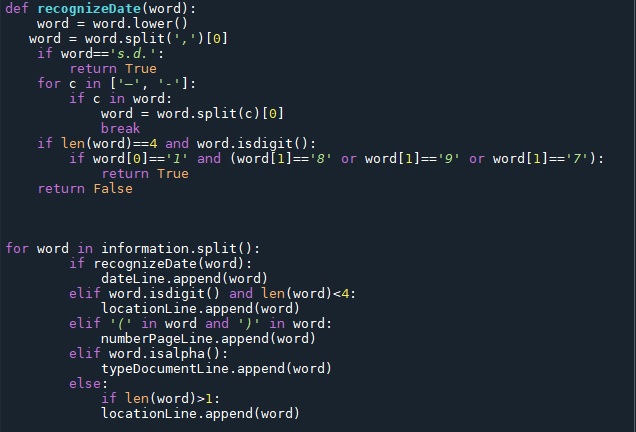
Dans le cas des inventaires, les données sont généralement déjà en partie structurées. Dans le cas de l’inventaire Perotin, si les informations suivaient un ordre, elles n’étaient pas systématiquement présentes. De plus, il nous a fallu aussi nettoyer plusieurs fautes de frappe. Les langages de programmations sont parfaitement adaptés à ce travail de structuration et permettent d’éviter un travail manuel fastidieux.
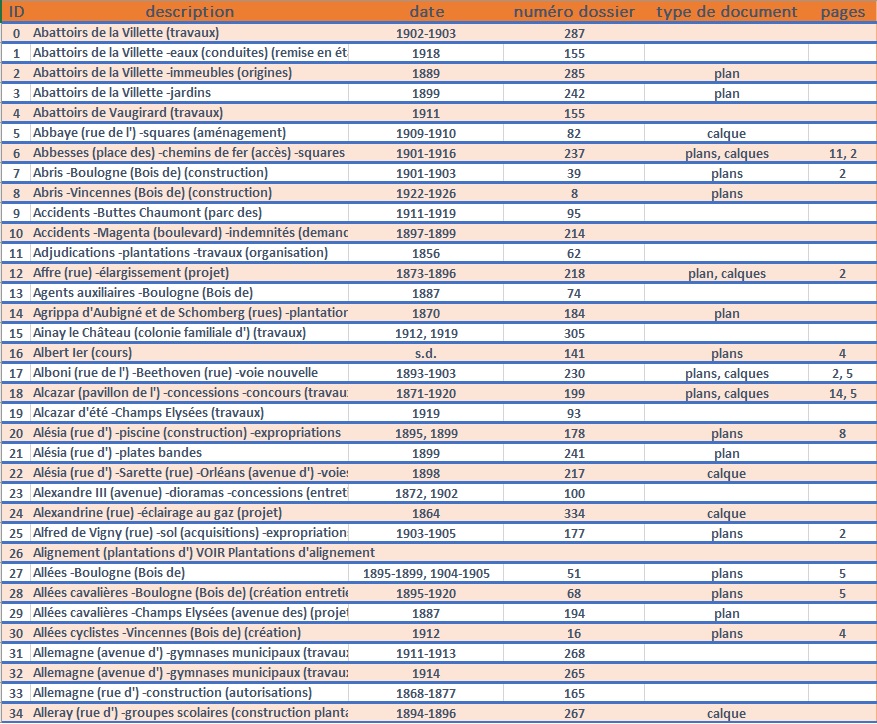
Le résultat final est un fichier informatique où les données sont structurées selon le modèle souhaité. Il devient alors possible de facilement sérialiser ces données au format TEI pour les intégrer à un système d’information, comme une base de données. Dans le cas présent, les chercheurs ont fait le choix d’intégrer leurs données à leur plateforme AtoM.
L’utilisation d’un langage de programmation, comme Python, est particulièrement intéressant sur des grands volumes de données, qu’elles soient issues d’un inventaire unique ou d’une série structurée à l’identique.