Biodiversité, analyse lexicométrique des documents d’aménagement du territoire
Dans le cadre de notre collaboration récente avec Morgane Flégeau, chercheuse en géographie du laboratoire de recherche LOTERR de l’Université de Lorraine, nous avons réalisé une analyse lexicométrique des documents d’aménagement du territoire portant sur la biodiversité. Cette étude s’est concentrée sur trois terrains d’études : la métropole du Mans, l’Eurométropole de Strasbourg et le PNR des Monts d’Ardèche. L’objectif était d’examiner la communication des acteurs publics et privés, en particulier les collectivités, sur les thématiques de la biodiversité, de la végétalisation et de l’animal en ville.
Les documents de planification et la méthode d’extraction de données
Pour chaque terrain, nous avons collecté un document de planification d’aménagement du territoire (PADD, PAS, SRADET, Charte) à trois ou quatre échelons : communal, intercommunal, régional et parc national. Au total, nous avons récupéré 59 documents répartis sur 70 fichiers PDF.
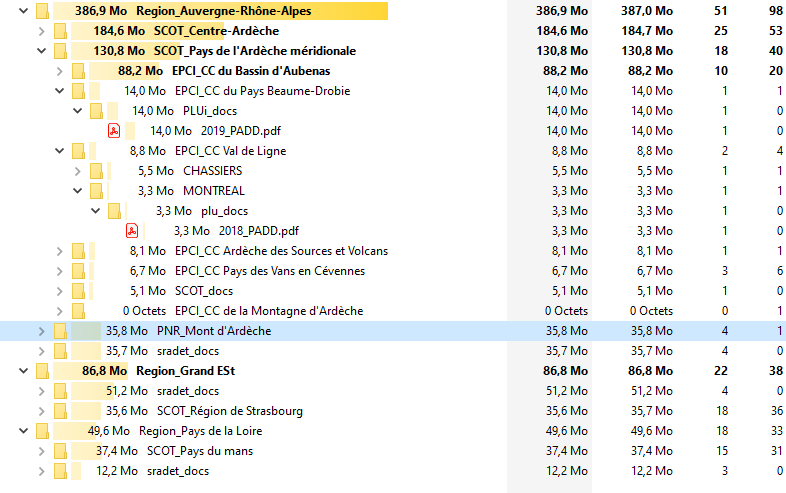
Malgré des spécifications communes, ces documents ne permettent pas d’exploiter des structures ou marqueurs communs en vue de l’extraction de données. De plus, certains d’entre eux utilisent des infographies qui n’étaient pas exploitables dans le cadre d’une analyse de texte.
- Suppression de pages contenant moins de 500 caractères.
- Exclusion des paragraphes avec plus de 60% de caractères non alphabétiques.
- Suppression des paragraphes trop récurrents (revenant dans plus de 10% des pages).
Ces valeurs ont été définies après plusieurs essais et évaluations. Ces méthodes, bien qu’imparfaites, ont permis de nettoyer automatiquement un corpus de plus de 3 000 pages. Ces dernières forment un ensemble segmenté en paragraphes et peut être subdivisé en sous-corpus par le biais de métadonnées diverses (terrains, échelon, type de documents, date etc.).
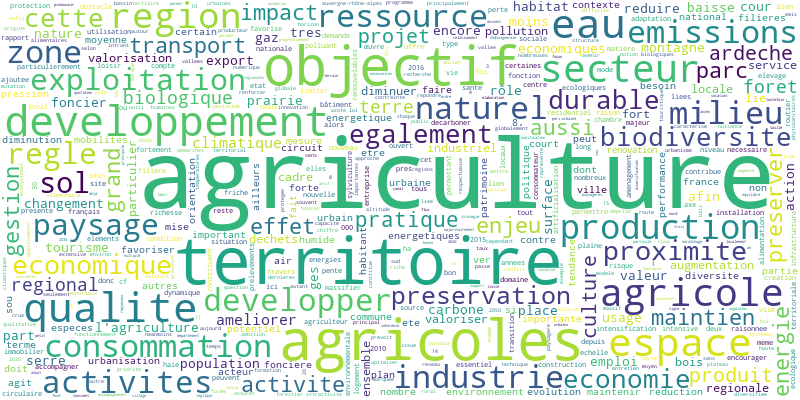
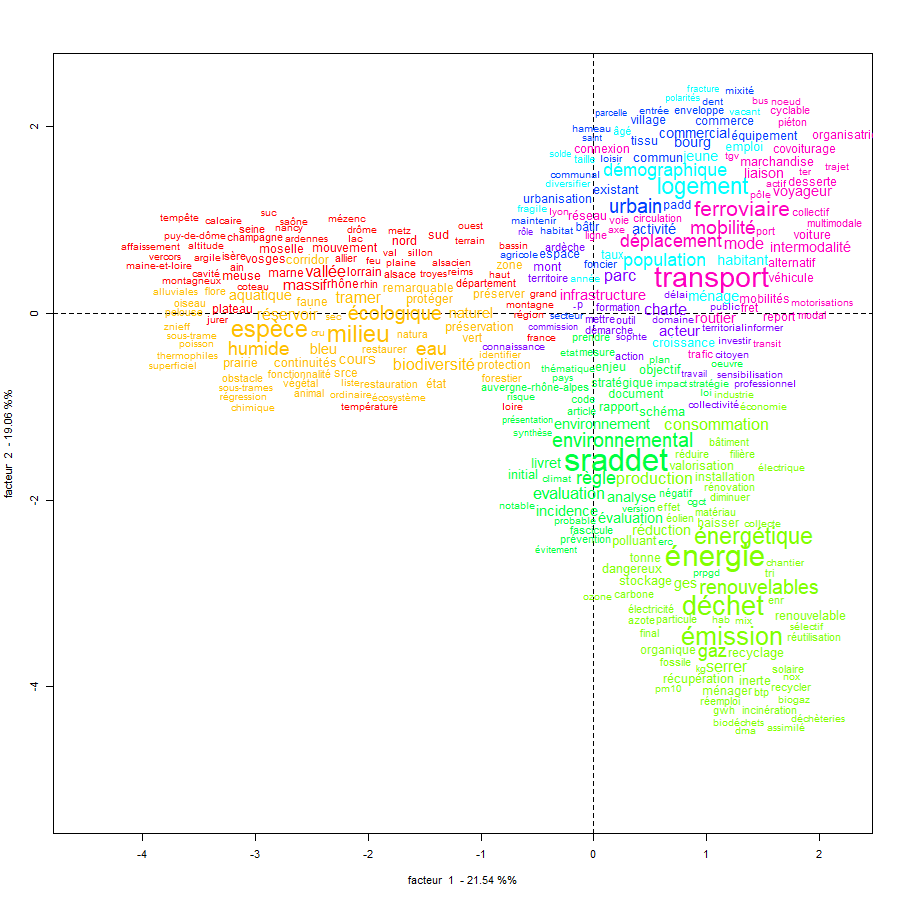
L’analyse lexicométrique
Ce corpus extrait et nettoyé constitue la base de l’analyse lexicométrique. Grâce à un script python, nous pouvons générer une série de sous-corpus en croisant : terrains, échelons ainsi que types de documents. A cela s’ajoute la possibilité de cibler plus précisément des segments du corpus (paragraphes) par mots-clés.
L’analyse est réalisée à l’aide des bibliothèques Python NLTK et FrenchLefffLemmatizer. Le processus consiste d’abord à découper le corpus en mots ou groupes de mots (tokenisation) et à normaliser les variations d’un même mot (lemmatisation). Ensuite, les mots indésirables tels que la ponctuation et les verbes sont filtrés.
Dans un second temps, nous avons produit une sérié de nuages de mots pour chaque corpus ainsi qu’une analyse des similitudes sur l’ensemble. Cette approche permet d’explorer en détail un corpus comprenant plusieurs documents sur différents terrains. Bien qu’elle génère un grand nombre de résultats à lire, elle offre une compréhension approfondie des relations entre les terrains et les types de documents.
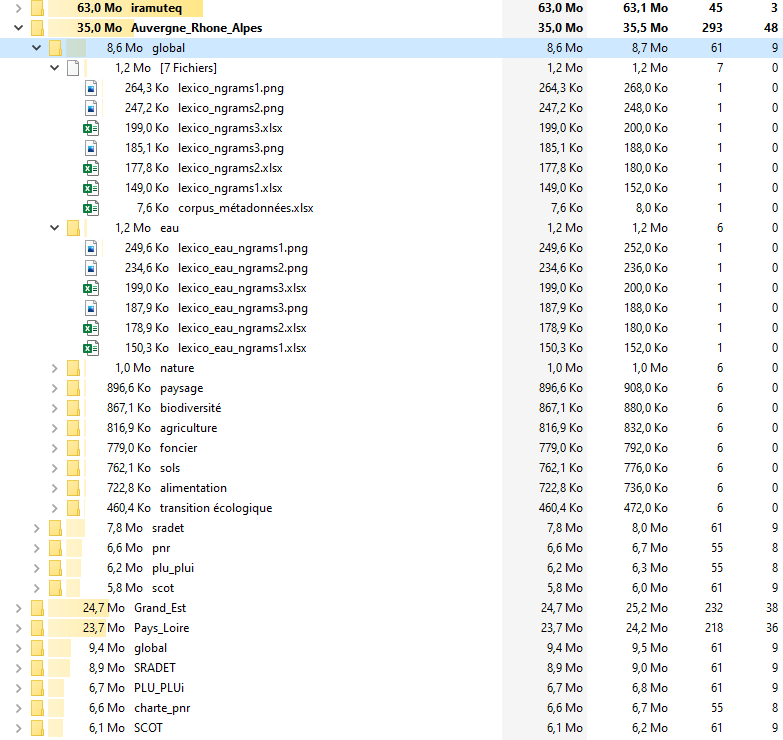
Le livrable
Nous avons fourni à la chercheuse un livrable comprenant les documents collectés, le programme python permettant de reproduire de façon automatisé la génération du corpus et les analyses, une documentation et une version Iramuteq du corpus.
Le programme est structuré pour permettre à une personne relativement néophyte (Il faut tout de même installer Python) de réutiliser le code pour produire de nouvelles analyses avec des paramètres différents à partir d’un notebook en quelques lignes de code documentées.
Dans le cadre de ce projet, nous avons fait le choix de développer un programme Python capable d’évoluer pour répondre aux futurs besoins. De nouveaux documents et terrains peuvent être ajoutés sans nécessiter de modification du code.