Europalg : mise en ligne sous Omeka
Suite à l’extraction de données réalisée pour le Centre Roland Mousnier, LeCube a mis en ligne le guide des sources, Les Européens en Algérie (1830-1962), de Corinne Gomez-Le Chevanton à travers le site web Europalg. Ce dernier repose sur le CMS Omeka et offre aux utilisateurs une base de données de plus de 3 500 sources via un moteur de recherche et un index thématique.
Omeka : un outil adapté à la valorisation de données de recherche
Omeka est un CMS (Content Management System) développé par l’organisation Digital Scholarship. Il offre aux chercheurs un outil collaboratif pour organiser et valoriser leur recherche. Il permet de saisir et de structurer simplement et rapidement les données selon un schéma collection/objet, ainsi que de les décrire à l’aide de métadonnées.
Ses avantages sont nombreux. L’outil est facile à déployer et à prendre à main. Omeka dispose d’une communauté active dans les sciences humaines et sociales et répond aux standards de la gestion de données en matière d’humanités numériques. Dans le cas du projet Europalg, le choix s’est porté sur la version Omeka-S, car celle-ci répondait à tous les besoins en plus d’être déjà utilisée par l’équipe de recherche.
Schéma de données Omeka
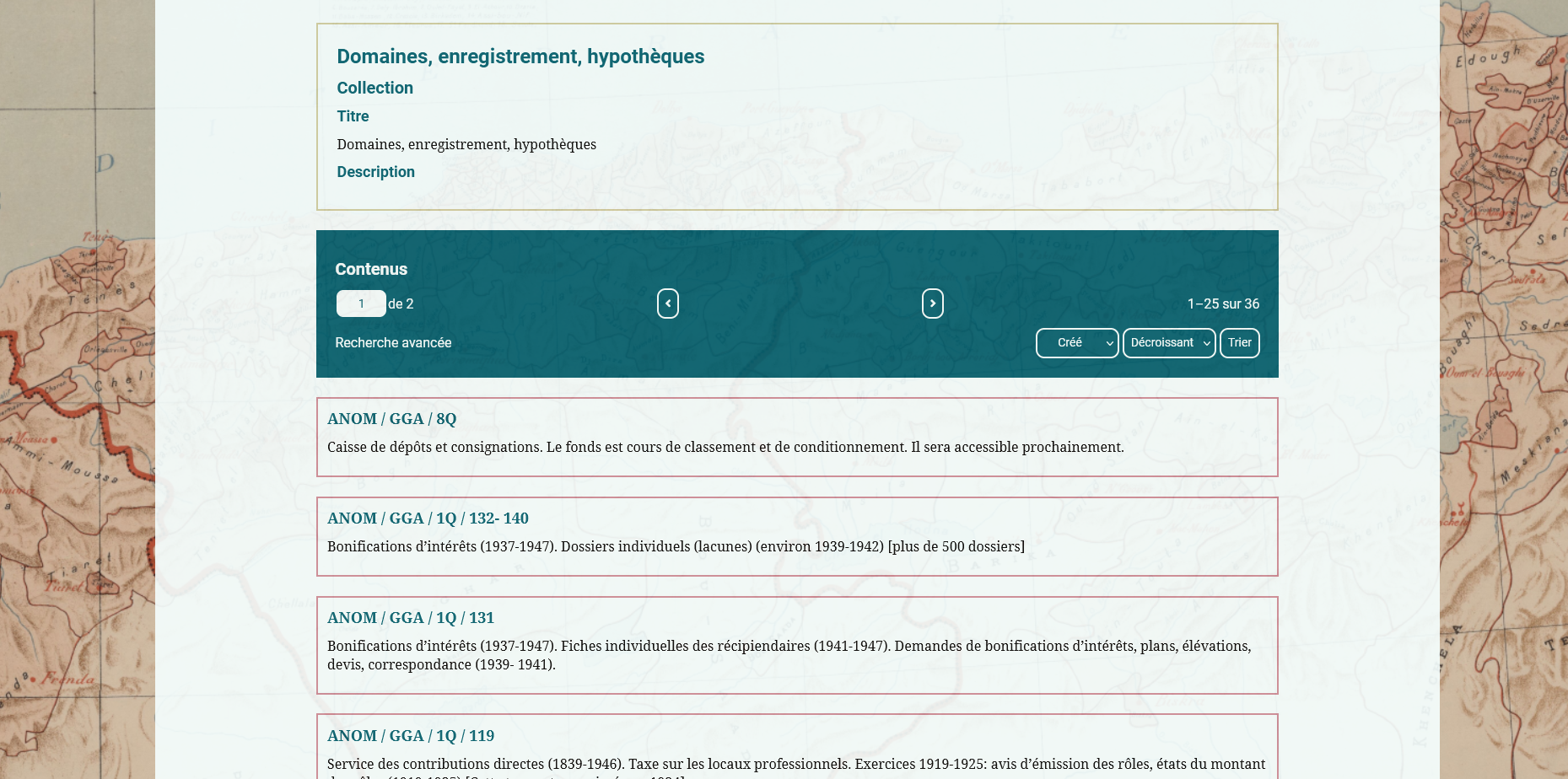
Le site Europalg doit restituer le guide des sources dans un format web à l’aide d’Omeka. Le travail d’extraction réalisé précédemment a permis d’extraire la donnée de l’ouvrage. Il convient maintenant de l’adapter au modèle d’Omeka et de concevoir un site dont la navigation valorise tous les éléments du guide des sources comme l’introduction ou l’index thématique.
Omeka gère les données avec MySQL, un système de gestion de base de données relationnelles. Cependant, son interface et son utilisation se rapproche d’une base de données documents. Europalg utilise trois types de ressources :
- Les items (traduit contenus en français dans Omeka).
- Les collections (items set selon la terminologie anglaise dans Omeka).
- Les pages.
Un item Omeka
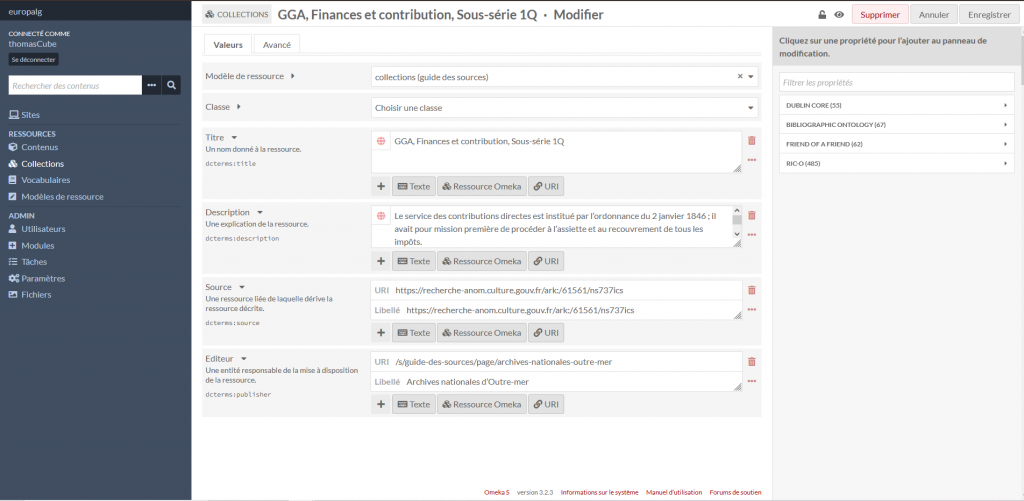
Un item est l’objet de base d’Omeka. Il représente l’objet à valoriser, ici des cartons d’archives. L’utilisateur peut décrire ces items à l’aide de métadonnées sous la forme de paires clés-valeurs. Omeka puise ses clés dans des vocabulaires comme Dublin Core. Il est possible d’en ajouter des nouveaux. Les valeurs de ces clés peuvent prendre trois formes :
- Un format texte classique.
- Une autre ressource Omeka (cela produit une relation entre ces deux éléments).
- Un URL ou un URI.
Dans le cas d’Europalg, chaque carton d’archive comporte une cote, une description et une borne chronologique. Le dernier élément (le champs Editeur) correspond à une page interne à Europalg rassemblant les collections archivistiques dans un index. Nous avons aussi utilisé la fonctionnalité d’annotation pour intégrer les notes de bas de page associées au carton.

Une collection Omeka
Une collection est un ensemble d’items et repose sur le même système de métadonnées. En ce qui nous concerne, il existe deux types de collections : les thématiques et les séries archivistiques.
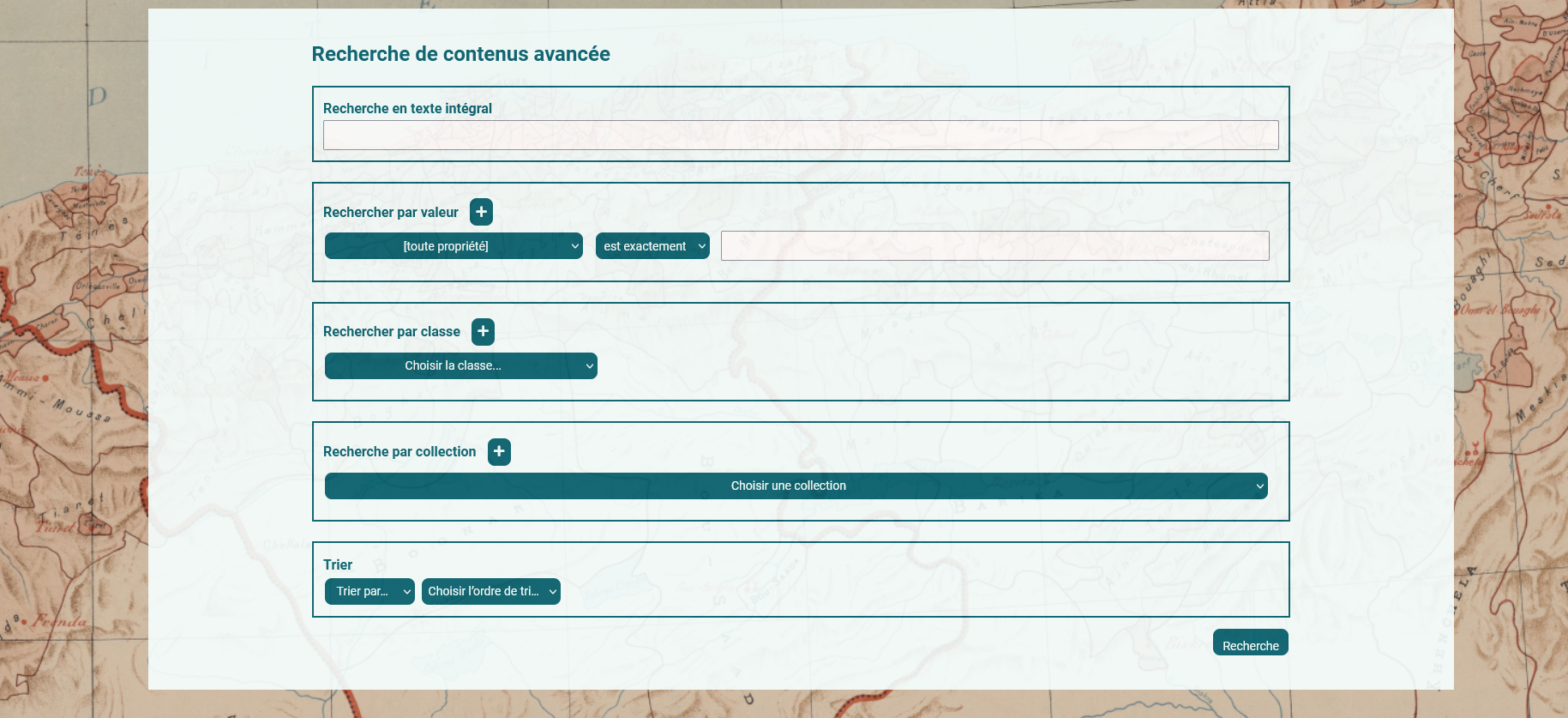
A noter qu’Omeka ne permet pas à une collection de contenir d’autres collections. Contrairement à d’autres bases de données documents, il y a une distinction assez rigide entre un item et une collection. Le guide des sources a besoin de cette fonctionnalité pour représenter l’arborescence de l’index thématique. Le module Collection Tree permet de contourner en partie cette limitation mais n’a pas donné pleine satisfaction. Nous avons donc décidé de reproduire cette hiérarchie à l’aide de balises HTML.
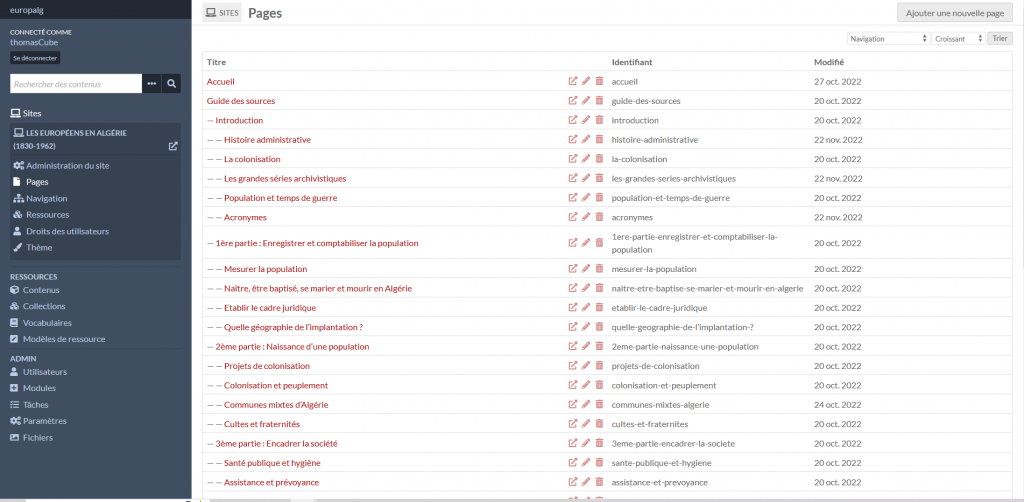
Une page Omeka
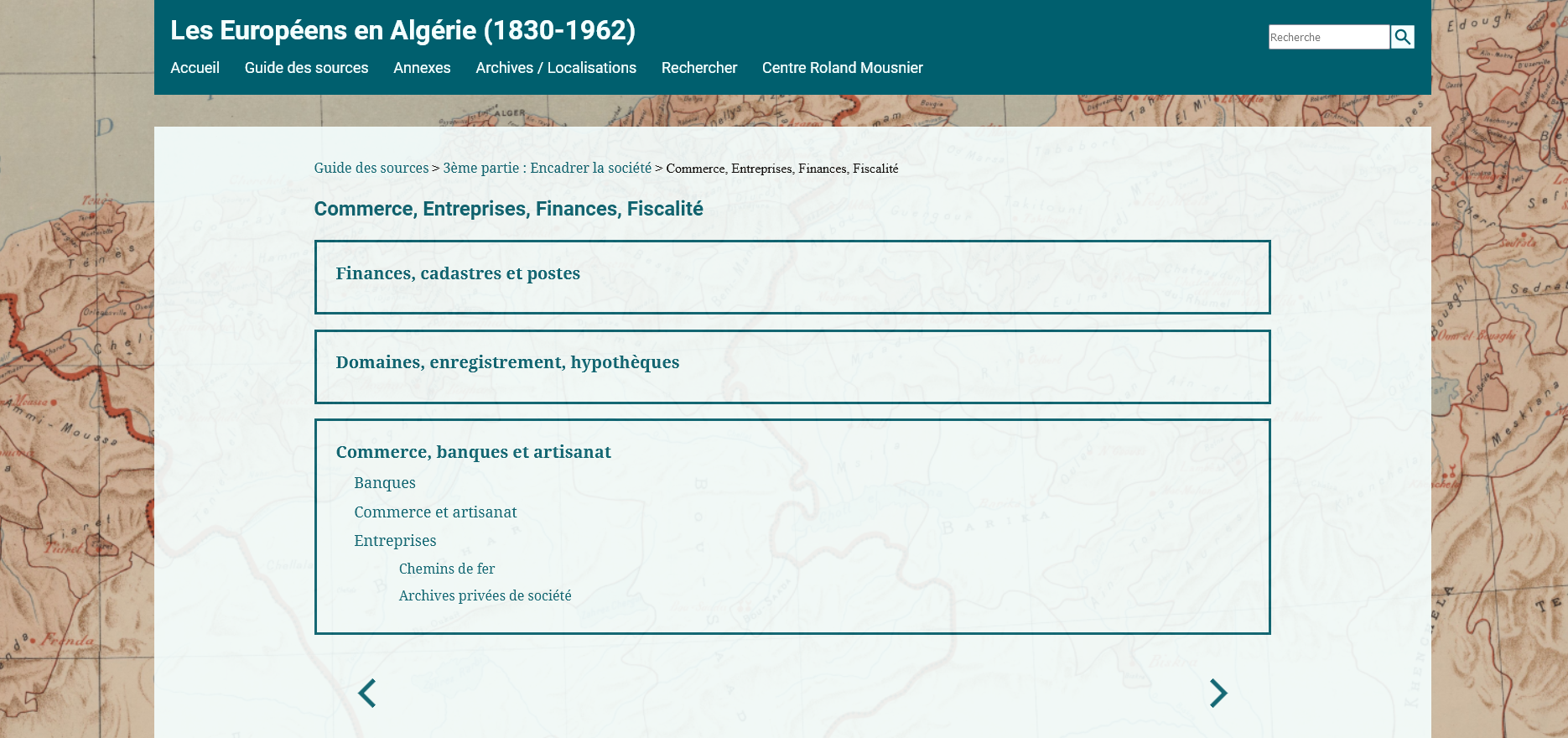
La page Omeka permet à l’utilisateur de produire des pages web plus classiques. Elles sont construites à l’aide de blocs à empiler. Dans le cas d’Europalg, il s’agit de la page d’accueil ainsi que des pages associées aux sections Guide des sources, Annexes, Archives / Localisations.
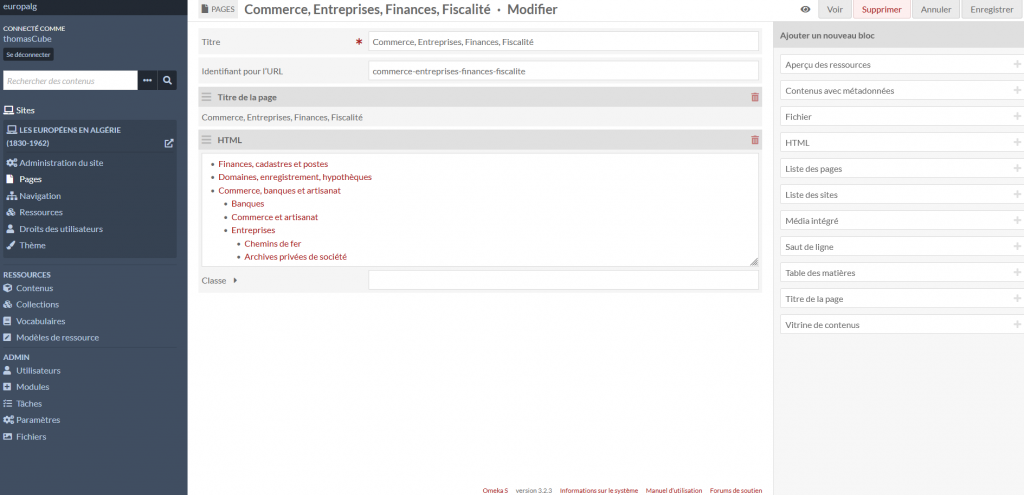
Les possibilités sont assez limitées en comparaison avec un CMS orienté édition d’articles comme WordPress. Il est néanmoins possible d’utiliser du code HTML comme ici avec une page de la section Guide des sources.
Intégration des données à Omeka
Dans le but d’adapter les données au modèle d’Omeka, nous avons utilisé un script Python afin de structurer les données et de générer les pages HTML de façon automatisée.
Une fois ce travail fini, il convient d’importer les données dans Omeka. Un module permet de le faire dans l’interface administrateur du site. Néanmoins il ne prend pas en charge certaines fonctionnalités importantes pour Europalg comme les annotations. L’intégration des données s’est donc faite directement dans MySQL.
MySQL : la base de données Omeka-S
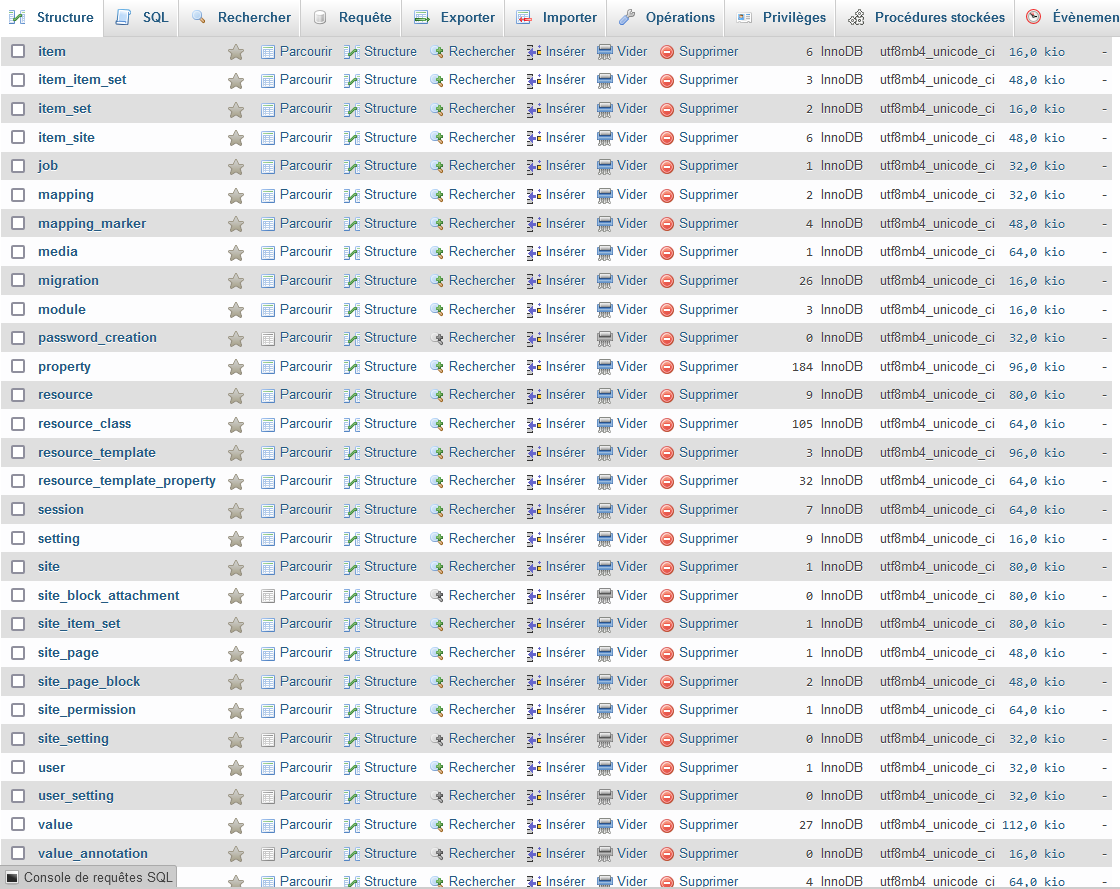
La base de données MySQL s’organise autour de plusieurs tables. Une partie d’entre elles porte sur les données à valoriser :
- La table resource liste l’ensemble des ressources présentes dans Omeka (collections et items).
- Les table item et item set organisent précise la nature de ces ressources dans le modèle Omeka.
- La table value comprend l’ensemble des champs et valeurs pour chaque ressource.
- La table value annotation liste les annotations éventuelles attachées à une entrée de la table value. Dans le cas d’Europalg, elles servent à représenter les notes de bas de pages.
Une seconde partie des tables MySQL portent sur les pages web, servant notamment à la navigation et à l’interface utilisateur :
- La table site page comporte l’ensemble des pages web du site.
- La table page block comprend les éléments constituant la page.
En définitive, 11 tables sont nécessaires pour importer les données du guide des sources sur le site Europalg. En plus des 7 tables citées plus haut, les données Europalg utilisent 4 autres tables :
- item_item_set pour lier les collections et items.
- item_site et site_item_set pour lier des ressources à un site dans le cas d’Omeka-S.
- fulltext_search pour rendre les données interrogeable dans le moteur de recherche Omeka.
Les données issues de l’extraction du guide des sources
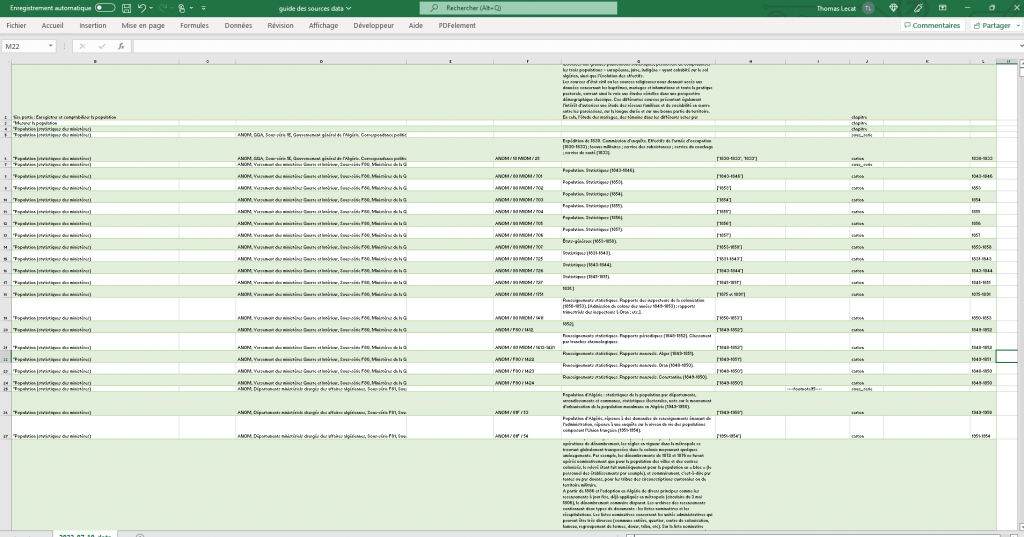
Suite à l’extraction de données réalisée sur le guide des sources, on dispose d’un fichier CSV contenant l’ensemble du guide des sources hormis l’introduction et les annexes.
Ces données ont été structurées dans un unique tableau de plus de 4 000 entrées. Chacune d’entre elles représente un élément du guide des sources (chapitres, séries archivistiques, cartons) et est accompagnée d’éventuelles descriptions ou notes de bas de pages. Les lignes représentant un carton d’archive comportent aussi des informations sur la thématique et la série parente.
Structuration des données à l’aide d’un script python
Les données propres aux items et collections sont, dans leurs majeures parties, déjà structurées. Il reste à assigner celles-ci aux multiples tables MySQL. Plus de travail est nécessaire pour proposer à l’utilisateur un index thématique organisant les collections.
Le guide des sources contient environ 300 thématiques réparties sur cinq niveaux. Les deux premiers niveaux, trois grandes parties et 19 chapitres, ne comportent pas d’archives contrairement aux trois niveaux suivants. Ces deux niveaux ont donc été utilisés comme pages dans Omeka. Chacune accueille en son sein leurs sous-thématiques. Ces dernières sont, elles, représentées comme des collections dans Omeka puisqu’elles doivent contenir des items (des cartons).
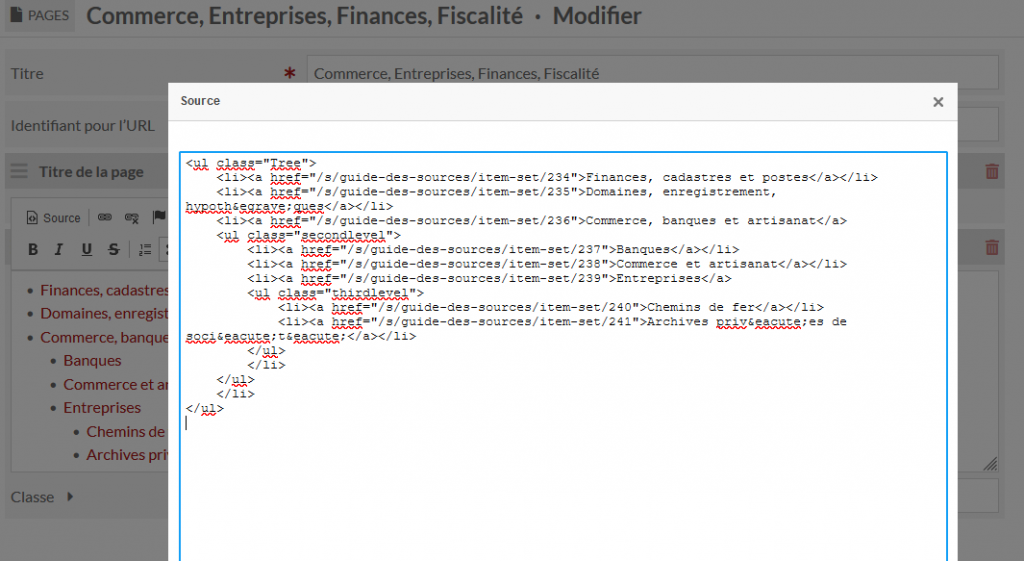
Pour chacune de ces pages, il a donc fallu produire un code HTML organisant les collections associées (leurs sous-thématiques) dans le bon ordre.
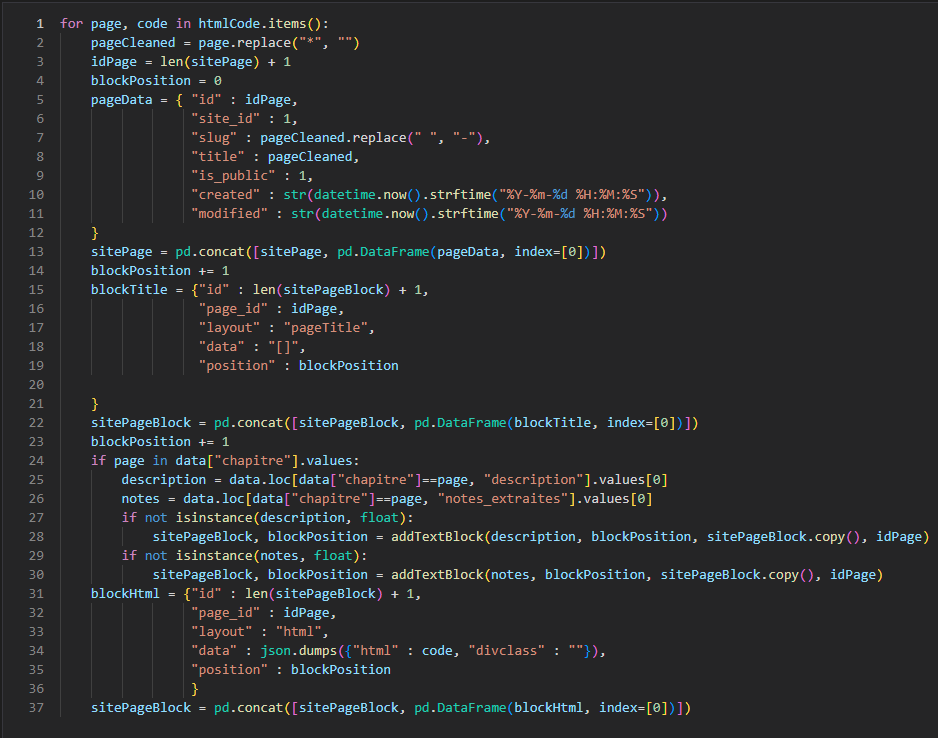
L’introduction, les annexes, la bibliographie et les pages archives ont aussi été générées de cette façon. Dans le cas de l’introduction, il a aussi fallu trouver un moyen d’intégrer les notes de bas de page dans le corps du texte pour faciliter la lecture.

Le site Europalg
Pour finir, ce travail permet à Europalg de valoriser le guide des sources de Corinne Gomez-Le Chevanton sur Les Européens en Algérie (1830-1962). Il donne la possibilité à l’utilisateur d’explorer une base de données de plus de 3 500 items par un index, thématique ou archivistique, ainsi qu’un moteur de recherche.