Europalg : Extraction de données d’un guide de sources
LeCube a réalisé un travail d’extraction de données dans le cadre d’un projet de valorisation du guide des sources, Les Européens en Algérie (1830-1962), de Corinne Gomez-Le Chevanton (Centre Roland Mousnier). L’enjeu était de passer d’un ouvrage de 400 pages au format Word à de la donnée mise en ligne sur le site Europalg.
Identification des données
La première étape est de lister les différentes informations à extraire. Le guide est constitué d’une liste de sources agencées thématiquement. Les données relative à ces dernières sont la cible de l’extraction. Elle se décomposent ainsi :
- Les titres.
- Les thématiques.
- Les séries.
- Les cartons.
- Les textes ou descriptions.
- Les éventuelles notes de bas de page.

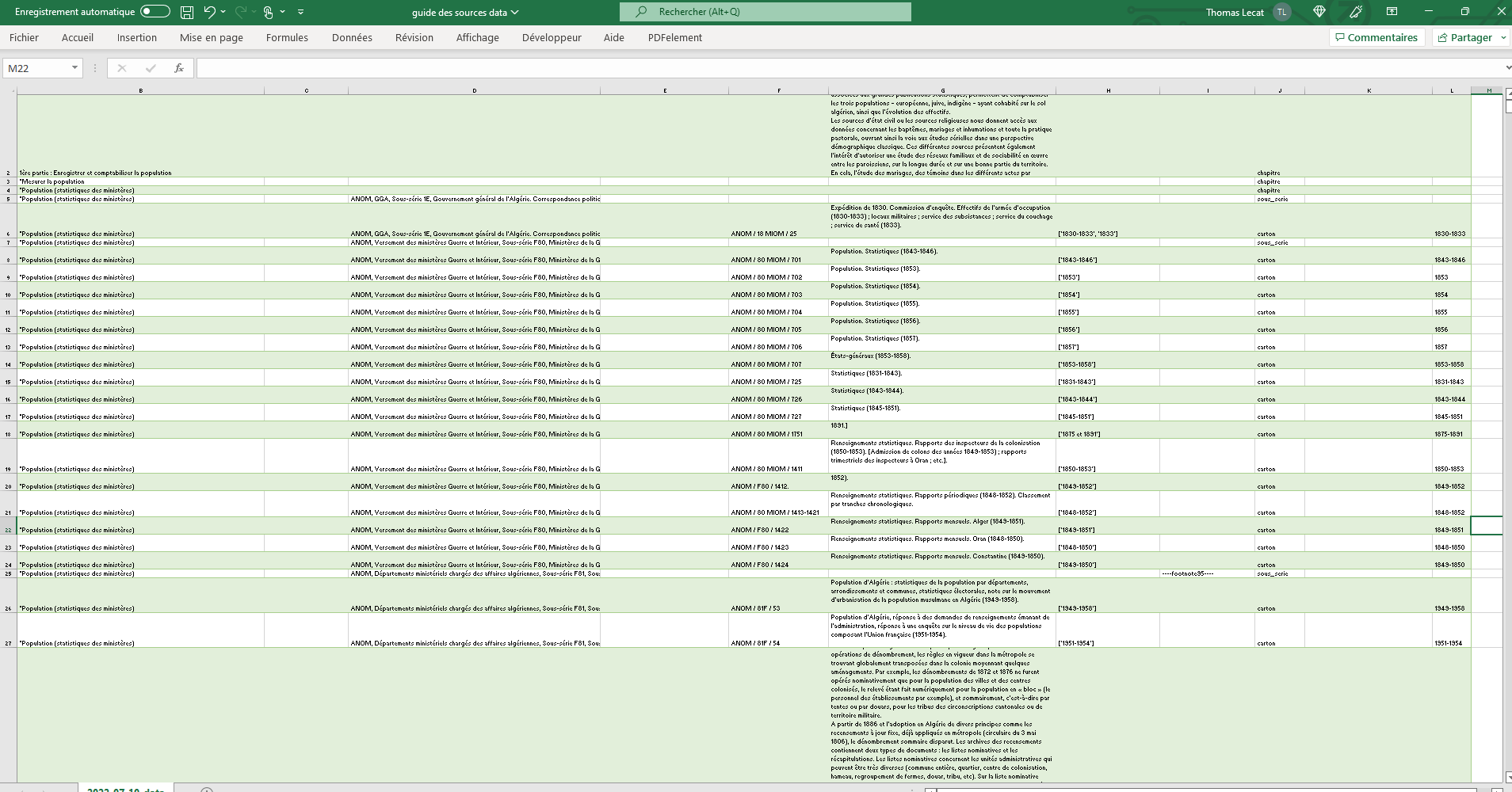
Nous retrouvons sur l’image ci-dessus (Page A), dans l’ordre, un titre de chapitre, une sous-thématique, la série archivistique, le carton, une description du contenu. Si cette structure est plutôt simple, elle connaît des variations et des cas particuliers.
L’ouvrage contient aussi une introduction, des annexes (qui sont des sources complémentaires), une table des matières et une bibliographie. Si ces éléments ne constituent pas la donnée essentielle, il était important qu’ils soient eux aussi transposer dans le format numérique.
Structure du guide des sources
A la suite de cette première étape, nous avons conçu un script python visant à détecter et isoler la donnée. La difficulté réside dans le besoin de produire un programme qui traite la plus grande partie possible du guide en étant le plus efficace. C’est à dire que l’effort mis dans le développement du code ne doit pas dépasser celui qui serait mis à traiter manuellement la donnée. Le processus est itératif. La première itération vise à produire un script cherchant à traiter le plus de volume le plus simplement possible. Pour la suite, il est possible d’utiliser plusieurs méthodes :
- Écrire plusieurs scripts pour traiter des parties différentes du texte.
- Enrichir le script pour qu’il puisse s’adapter.
- Développer un script plus efficace permettant de traiter un plus grand volume.
Avant de commencer ce travail itératif, il faut tout d’abord détecter des structures de texte et choisir sur laquelle s’appuyer pour débuter le processus d’extraction.
Des variations dans la structure du texte
Le guide des sources est un ouvrage scientifique cherchant à ordonner des sources. La page A, vue plus haut, suit une des structures les plus récurrentes. Le texte est agencé en chapitres listant des cartons groupés par séries archivistiques. Le format normé des séries et des cartons les rend assez simple à détecter. Cela permet d’isoler le texte chapitre par chapitre, puis série par série, et enfin carton par carton. La donnée est ainsi atomisée très rapidement.



Cependant, comme on peut le voir sur la page B ci-dessus, il existe des petites variations qui complexifient cette structure. Les sous-thématiques (en italiques) peuvent aussi bien être placées avant (page A) ou après (page B) les séries. Il arrive aussi que dans un chapitre les séries soient omises car elles ont déjà été citées précédemment.
De plus des variations beaucoup plus importantes existent aussi. Le guide des sources contient des sources bibliographiques (page C) ou des sources numérique ou particulière (page D) suivant des formats très différents.
Comment traiter ces variations ?
Plusieurs éléments permettent à un programme de lire de façon automatique la structure de la page A et B. Le texte peut être lu en paragraphes puis en lignes. Le second paragraphe de la page B contient ainsi 4 lignes :
- La série.
- Une thématique.
- Le carton.
- La description du carton. Si dans Word, cette dernière apparaît visuellement sur plusieurs lignes, il s’agit bien d’une seule et même ligne (lue comme tel par l’ordinateur).
Ces trois premières lignes comportent des éléments pouvant les identifier. Les séries et les cartons commencent toujours par des mots-clés (les centres d’archives) suivis respectivement par une virgule et un slash. La sous-thématique est en italique. La description s’identifie par élimination et se rattache à l’élément la précédant (ici le carton qu’elle décrit).
L’ordre des éléments n’a plus autant d’importance. Il est possible de catégoriser chaque élément indépendamment selon leurs formats spécifiques. Cette méthode permet de traiter la grande majorité des données. Néanmoins les sources bibliographiques (page C) ne le sont pas et certains cas particuliers causent un grand nombre d’erreurs. (page D).
Le script python
Certains projets d’humanités numériques peuvent demander de mettre en place un processus d’extraction pérenne. Dans notre cas, l’objectif est d’extraire un volume de données fini. Il n’est donc pas intéressant de développer une solution pour traiter l’entièreté du texte. Il est plus efficace de corriger manuellement les erreurs d’extraction.
Finalement, nous avons fait le choix de nous appuyer sur la méthode vue plus haut. Le script isole le texte en plus petites unités, d’abord par chapitres, puis par paragraphes et enfin par lignes. Puisqu’une large partie des sources bibliographiques sont contenues dans des chapitres dédiés à celles-ci, ces derniers sont traités à part après le découpage par chapitre. Le reste est corrigé manuellement.
Décomposition du guide des sources en plus petites unités
Nous avons donc divisé le guide des sources en unités indépendantes par chapitres afin de manipuler des plus petites unités indépendantes et afin de conserver la structure thématique. Cela nous a aussi permis de tester notre code sur des parties spécifiques et de détecter les erreurs plus facilement.
Le script subdivise ensuite ces chapitres au niveau du paragraphe pour exploiter la structure décrite plus haut.
Catégorisation des données
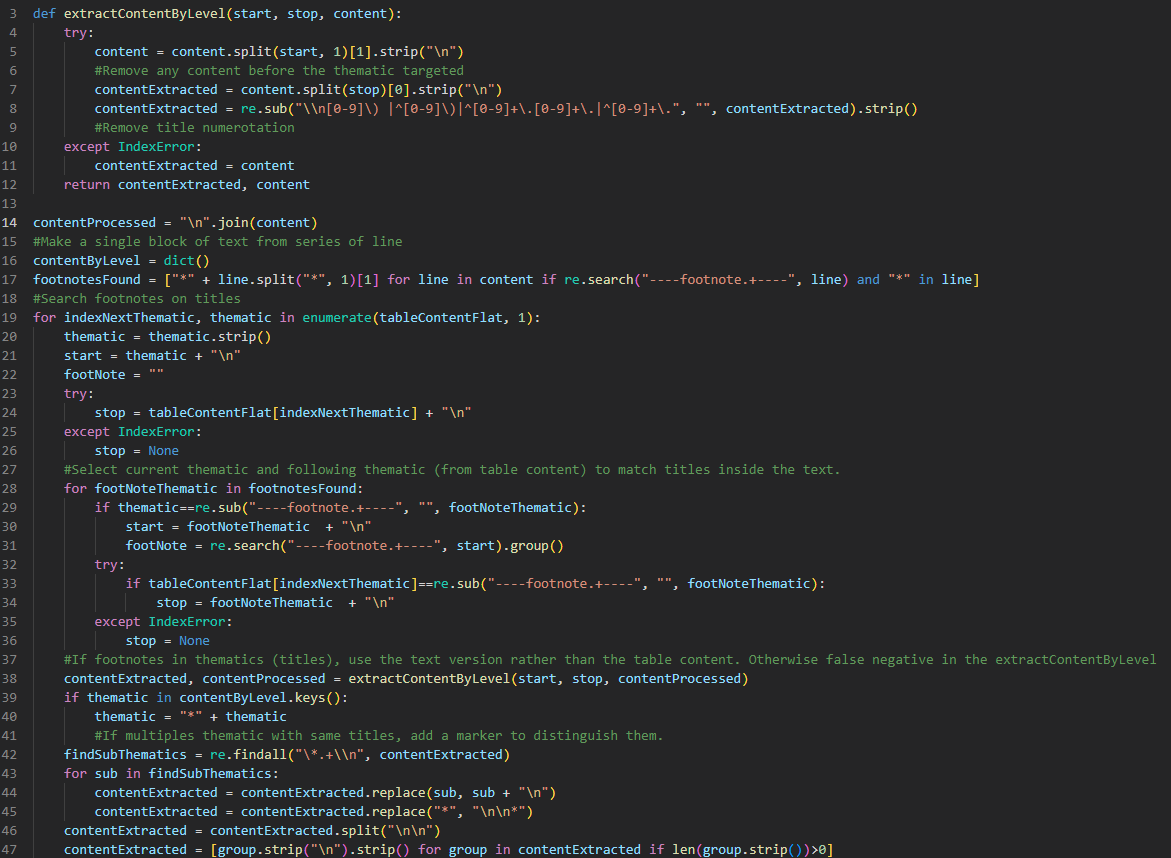
Suite à cette décomposition, nous pouvons catégorisé tous les éléments. Cette étape se déroule à l’échelon du paragraphe. Certains paragraphes peuvent contenir quatre types de données (thématique, série, carton, description), alors que d’autres, peuvent en comprendre seulement deux (carton et description). Contrairement au chapitre, les paragraphes ne sont pas indépendants les uns des autres.
Le script Python traite ensuite ligne par ligne chaque paragraphe pour identifier la nature de la donnée. Finalement, le programme déduit les relations entre ces données selon une lecture linéaire et logique du chapitre. Par exemple, tant qu’une nouvelle série n’est pas identifiée, les cartons sont attribués à la dernière série détectée.
Une dernière étape a été d’extraire les notes de bas de pages et les dates utilisées dans les descriptions.
Des données exploitable
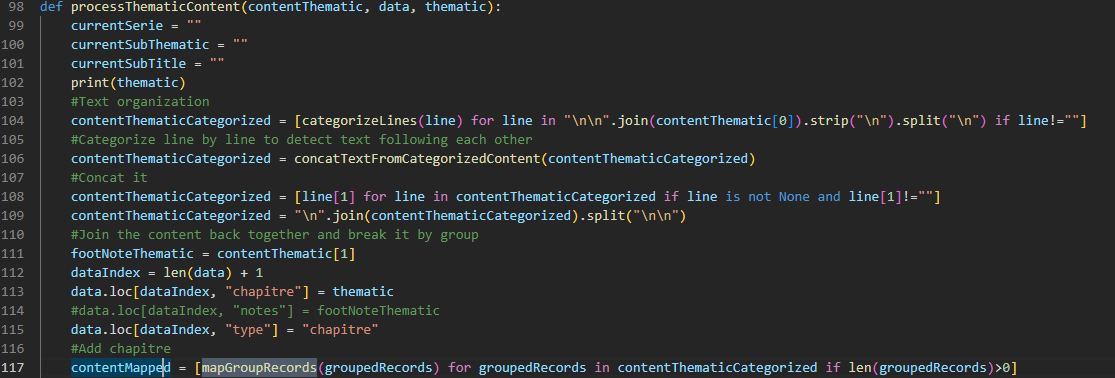
Pour finir, nous disposons d’une base de données au format CSV. Avec plus de 4 000 entrées, elle contient l’ensemble des informations du guide des sources. Chacune d’entre elles représente un élément du guide des sources (chapitres, séries archivistiques, cartons) et est accompagnée d’éventuelles descriptions ou notes de bas de pages. Les cartons d’archive comportent aussi des informations sur la thématique et la série parente. La prochaine étape est de valoriser ces données sur le web à l’aide d’Omeka, un CMS (Content Management System) très utilisé en sciences humaines et sociales.